推荐系统介绍
推荐系统是流量平台中不可缺少的一部分,旨在从平台海量的内容中精准的选出用户可能该兴趣的内容推送给用户,从而吸引用户使用该平台,获取流量。通常被推荐的内容记为 item,有时候也叫物品,这篇博客会把 item、内容、物品都混着用。推荐系统需要从数以亿计的 item 中选择几个推荐给 user,这需要对 user 和 item 的关系进行建模。
推荐系统的链路

当用户的请求到达服务器后,服务器首先会获取用户的相关数据,然后基于这些数据进行 召回 得到几千个 item 列表。随后获取每个 item 的数据,与用户数据一起进入 排序 阶段,把用户最可能感兴趣的排在前面。排序结束后,会将排在前面的几个 item 发送给用户展示。
这里分成召回、排序两个阶段的原因是,item 数量非常非常多,通常是数以亿计的,如果逐一去看用户对每个 item 是否感兴趣,计算量太大,做不到实时,用户的一个请求到来不知道要等多久才能返回结果。召回阶段就是考虑到大多数内容都是用户不感兴趣的,用简单的策略快速地从数以亿计的 item 中过滤掉用户不感兴趣的,接下来就只需要对这几千个 item 进行处理,根据用户感兴趣的程度进行排序。
排序的目标是把用户感兴趣的 item 排在前面,排序的方式通常是预测点击率等指标,对每个 item 都预测一点击的概率,依据这个模型预测的分数进行排序,因为用户想点击的通常是自己感兴趣的。点击率的预测可以理解为如下的逻辑:
if (用户性别==男 && 作者性别 == 女 && 内容类型 == 艺术照 && 作者粉丝数 > 10000):
pred = 1
if (用户性别==男 && 作者性别 == 男 && 内容类型 == 艺术照):
pred = 0
else:
pred = 0.5
现在搜广推都使用了深度学习模型,但如果用深度学习模型对几千个 item 都进行计算,计算量还是太大,为了解决这个问题,排序被进一步拆分为精排和粗排。粗排使用比较小的模型从几千个 item 排序选出 top300 的 item 交给精排模型,精排模型通常比较复杂,对这300个 item 进行进一步的排序。深度学习模型的优势不仅仅在于强大的建模能力,也在于训练和部署的方式相对单一,更容易开发通用的系统来迭代模型,同时也使得工业界和学术界的交集变大了。
召回的目标是提高召回率,精度可以低;而排序的目的是提高精度,保证单次推荐的精确性。即使精排能做到非常高效,对所有 item 进行排序,召回也是不可少的,有一个例子可以帮助说明这个观点:
一个人看了非常多并且只看了“美女”标签的内容,按道理精排模型肯定把所有“美女”的 item 前面。那是不是我们全部推荐“美女”的 item 效果就最好呢?不一定。召回要有多样性,有些类别虽然打分不一定最高,但是也要给机会。然后你就惊喜地发现,喜欢看美女的用户,往往也关心国家大事。
关于粗排和精排,粗排的作用是用更小的模型预先筛选一部分给精排使用,这是出于计算量考虑的妥协,本质上还是希望得到更精确的排序。通常,粗排使用简单的双塔模型,不会使用交叉特征,这样可以预先算好 item 侧的embedding(因为 item 几乎不会被改变),减少serving的计算量。粗排优化的思路一般是向精排看齐。
AB测试
推荐算法的效果需要通过可靠的方法进行验证,现在的推荐系统都是通过AB测试进行评估,并使用假设检验评估实验结果的置信度,保证实验结论是可靠的。
AB测试的基本思想是对用户进行划分,例如为了验证一个新模型B比之前的模型A更好,把用户划分为两部分,50%的用户的请求让A模型进行预测,50%的用户的请求让B处理。进行一周的实验之后,如果使用B模型的用户的日活、留存率等指标更高,且经过假设检验后p值小于5%,那么有理由认为B更好,于是可以把A模型替换成B模型服务于所有用户。上面这种划分用户的方法叫分桶,一般一次不会只对一个模型进行实验,无论是为了调参还是优化模型,一次会进行多个实验。有N个实验模型就需要划分N+1个桶,一个留给 baseline,其余的作为实验组与 baseline 比较。
链路中不同环节为了实验都需要分桶,为了不互相影响,这个时候需要分层。还是假设一个app一天有100w个请求,有4个召回模型需要实验,有5个排序模型需要实验,一个请求可以先随机划分给4个召回模型中的一个,之后再随机划分给一个排序模型中的一个。由于划分都是随机的,因此可以认为每个召回模型占用的25w个流量均匀的包含了5个精排模型,于是在对比不同召回模型的时候就可以忽略掉精排模型的影响。这样就相当于把流量分成了2个流量层,召回占一个流量层,排序占一个流量层,二者可以认为是独立的,在进行实验的时候可以不考虑其它层的影响。
ab测试除了起到测试的作用,也起到上线的作用。一个模型被推上线后,不会有流量推给它,而是先会给很小的流量,并逐步增大,在这个过程中如果没有出现问题,才会进行实验。
针对滞后的指标,需要长期实验,推全的时候不会完全推全,会保留一部分长期观察,为此会进行反转实验,就是把实验组的一半流量回退到 baseline 进行对比,变成一个流量更小的实验长期观察。
召回
召回用于快速的从数以亿计的 item 中筛选出用户可能会感兴趣的几千个 item 。通常召回会通过多种算法获取 item ,然后合并到一起并去重,这称为多路召回。最经典的召回算法是协同过滤算法。
协同过滤算法
协同过滤(collaborative filtering, CF)算法其实是2个算法:这是基于用户的协同过滤 userCF,和基于物品的协同过滤 itemCF。前者的思想是记录兴趣相似的用户,把各自没有看过的 item 互相推荐;后者的思想是,根据物品之间的相似度,给用户推荐与用户浏览过物品的相似物品,比如很多人同时喜欢衣服A和B,可以认为两件衣服类似,如果有人只浏览过A,就可以给他推荐B(“喜欢这件商品的人也喜欢xxx”)。
userCF和 itemCF
问题是用户和物品的相似度如何衡量?答案是使用 user-item 矩阵。该矩阵记录了用户与物品的交互信息,每行对应一个 user ,每列对应一个 item ,交互过的物品就是 1,没有交互过就是 0。于是用户的兴趣可以用行向量表示,那么用户之间的相似度可以用行向量之间的余弦相似度衡量。类似地,物品之间的相似度可以根据列向量之间的余弦相似度衡量。当然,别的相似度指标也可以,比如交并比。
具体来说,假设要给用户$u$推荐物品,考虑与$u$最相似的$k$个用户$u_1,\cdots,u_k$, user CF通过以下方式估计用户$u$对物品$s$的打分:
\[{\rm score}(u,s) =\sum\limits_{i=1}^k {\rm sim}(u, u_i){\rm score}(u_i,s)\]其中${\rm sim}(u,u_i)$表示用户$u$与用户$u_i$的相似度,只要找出评分最高的几个物品给用户$u$做推荐就可以了。 item CF则是考虑用户$u$交互过的$k$个物品$s_1,\cdots,s_k$,通过以下方式估计用户$u$对$s$的打分:
\[{\rm score}(u,s) =\sum\limits_{i=1}^k {\rm sim}(s,s_i){\rm score}(u,s_i)\]其中${\rm sim}(s,s_i)$表示物品$s$与$s_i$之间的相似度,同样找出评分最高的几个物品给用户做推荐。
召回是为了根据 user 得到 item , userCF是根据 user 得到类似的 user ,再根据 user 得到 item ,简单记为u2i2i。与之对应的, itemCF是 u2i2i。考虑到 user 和 item 数量非常多, user - item 矩阵的大小是几亿乘几亿的矩阵,不可能保存这么大的矩阵。但是这个矩阵是稀疏的,我们可以记录每个 user 交互过的 item 列表,以及访问过 item 的 user 列表,这样就得到的压缩的行、列向量表示,进一步可以计算出与每个 user 相似的 user ,与每个 item 相似的 item ,进而实现u2u2i和u2i2i的协同过滤。
协同过滤算法的缺陷
- itemCF:小圈子用户错误的导致物品相似,解决这个问题需要识别小圈子。Swing模型会考虑用户重合度,重合度高的用户在计算物品相似度的时候权重低,保证喜欢同一个物品用户有足够的多样性
- userCF:需要降低热点物品对相似度的影响
多路召回
实际的推荐系统为了保证多样性,会进行多路召回。每个召回的支路会按不同的算法或者策略进行召回,可以划分为非个性化召回以及个性化召回(实际根据业务需求会有几十个召回支路,这里列出了一些常见的):
- 非个性化召回
- 热点召回
- 基于新鲜度召回
- 个性化召回
- 向量召回
- tag召回
- 协同过滤召回
- 地理位置召回
- 关注列表召回
- 相似作者召回
- 还有一些fancy的算法有TDM、Deep Retrieval、多向量召回、RL召回、生成式召回等。
- 缓存召回:把之前精排的 item 缓存起来,作为一路召回
为了实现高效的召回,需要对海量的 item 建立索引,索引分为2类:正排索引和倒排索引。正排索引指根据uid或 item id获取属性的索引,而倒排索引指根据属性获取uid或 item 的索引。
实现上,每个召回支路会用一个id表示。多路召回得到的多个序列会进行融合,一个常见的融合算法是snake merge算法,简单讲,就是每个召回分支轮流出一个,如图所示:

merge的时候会进行去重,还可以给每个召回支路加优先级、配置quota等,可以参考这里。
向量召回
向量召回会给每个 user 和 item 都得到一个embedding,在召回的时候根据 user embedding检索最接近的哪些 item embedding作为召回结果。
双塔模型
向量召回通常使用双塔模型。双塔模型是后融合的,召回为了时延考虑需要提前提取好特征,不能用前融合,尽管前融合通常效果更好。
item 的 embedding 通常由 item 的一些特征输入 MLP得到,会预先计算好; user 的 embedding,用 MLP 处理用户的年龄、性别等特征以及用户交互过的 item ,输出得到 user embedding。
双塔模型的训练有几种方式:
- point-wise,相当于二分类,预测点击概率。一般正负样本比例1:2或1:3,不知道为什么。。。
- pair-wise,一个正样本,一个负样本
- list-wise,一个正样本,多个负样本。infoNCE loss,类似于对比学习。 为了适应用户临时的偏好,召回模型也需要 online learning,每隔几十分钟更新一次。
双塔模型最重要的细节是正负样本的选取,选取的考量包括简单与困难负样本、热门物品的打压、伪负例问题等等,这里不详细介绍。
近似最近邻
在数亿级别的 item 向量中检索最近邻计算量很大,为了时延考虑只会近似去求最近邻(Approximate Nearest Neighbor)。一些常见的近似最近邻算法有:
- KD树
- 乘积量化(product quantization, PQ)
- 局部敏感哈希(Local Sensitive Hash, LSH)
- Hierarchical Navigable Small World(HNSW)索引
- INT8量化+GPU暴力计算,效果好但需要更多计算资源,效果的提升不一定能抵消新增计算的资源。
这种向量检索是非常常见的需求,有很多向量数据库实现了,比如Faiss,Milvus等,一些公司会有自研的向量数据库。
曝光过滤
召回的时候需要去掉用户近期看过的物品,这就是曝光过滤。曝光过滤一般用布隆过滤器这个数据结构实现,它算是哈希表的一个改进,用来实现类似于集合的功能。优点是占用空间比哈希表少,查询快(保证是 $O(1)$ 的复杂度),缺点是只能判断“一定不在集合里”,和“可能在集合里”,是一个偏保守的策略,适用于需要严格过滤的情况。布隆过滤器无法删除元素,于是有了一个改进计数布隆过滤器,具体就不展开了。
排序
推荐系统中,排序阶段需要针对给定的 user ,按用户对 item 的感兴趣程度进行排序。通常做法是输入 user 和 item 的特征,由神经网络模型预测点击率之类的指标,然后根据这个指标的大小进行排序。排序模型最重要的是特征,其次是使用的深度学习模型。因为排序的依据是特征,这是排序的根本。
特征
特征是判断 user 对 item 是否感兴趣的依据,通常特征可以分为三类:
- 直接特征:
- user 画像:
- 用户ID、性别、年龄、学历、注册时间、活跃度、是否是新用户等
- 用户最近的点赞率、收藏率、常看的内容tag、感兴趣的话题等
- item 画像:
- 物品ID、发布时间、发布地点、内容特征、tag、字数、视频分辨率、品牌等
- 物品点击率、点赞率、作者的ID、作者粉丝数量等
- 物品受众性别占比、年龄分布、地域等
- 场景特征:
- 用户的手机型号、手机电量、网速等
- 当前的经纬度、城市、当前时间、节日等
用户和 item 的ID类特征非常重要,但是没有泛化性。
- user 画像:
- 交叉特征:把两个直接特征相乘得到新特征
- 用户行为特征:例如,用户点赞过的 item 列表
在输入到神经网络之前,需要把特征都转化为连续值。离散特征通常的处理方式是输入embedding层,这是是通用且有效的方法;连续特征可以分段离散化(分桶),或者利用累积密度函数归一化等。还有一些特征,比如点击数,虽然取值是离散的,但是长尾效应严重,可以取 $\log(1+x)$,或者归一化成点击率。
推荐系统会使用大量的特征,很多特征都是稀疏的。例如每个用户都有一个ID特征,每个 item 也有一个ID特征,embedding数量很多亿个,但是对于一次推荐,只会用到很少一部分,这是特征的稀疏性。数学上来说,这些特征可以用one-hot表示,其中大多数都是0,所以说是稀疏的,0越多越稀疏,也就是一个特征的取值集合越多,越稀疏,所需要的embedding数量也越多,这会导致参数量过多,泛化性降低。通常对于过于稀疏的特征,会对特征进行分桶,降低特征稀疏性,或者淘汰很少使用的embedding,因为这样的embedding没有经过充分的训练,并且由于出现次数少淘汰了影响也不大。
不同的推荐业务特征差异非常大,电商、图文、视频推会有很多独有的特征,各种很细的业务特征就更多了。工业界的推荐系统开发过的特征会有几万个,输入到模型的则会有几千个特征。
特征服务
工业界的推荐系统会把每个特征用一个id表示,考虑到特征基本都是离散的,有不同的取值,而且不同特征数据类型也会不同(int、float、string等),为了统一管理,把它们全部计算哈希转换成int64类型。于是任意一个特征的取值可以用id+哈希值表示,这个记为FID,一个FID对应一个离散特征的取值。通过统一的FID表示,推荐系统里不同的服务程序就方便统一管理了,模型里也可以直接用FID获取对应的embedding。虽然哈希可能存在哈希冲突,但是冲突概率较低,并且embedding本身也有能力表示多个语义,因此认为哈希冲突不影响模型效果。
特征交叉
交叉特征指把直接特征组合成新特征。那么为什么交叉特征有效?可以从例子来看:
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
特征交叉可以是 user 和 user 特征交叉,也可以是 user 和 item 、 item 和 item 交叉。特征的交叉也可以在不同粒度进行: user 和 item 都有属性,也许具有某个属性的 user 很喜欢具有某个属性的 item ,那么可以在属性层面进行特征交叉,这样就是一个更细粒度的交叉,比如某个性别的人很喜欢某个品牌的商品。
尽管交叉特征很重要,但是MLP理论上能拟合任意函数,是否有必要人为构造交叉特征呢?答案是有必要的,一些论文表明神经网络不善于学习二阶特征,MLP天然是一个分段线性函数,并不倾向于学习二阶特征。因此,显式的引入二阶特征是很有必要的,在特征交叉方面有相当多的工作。
FM和FFM
FM指Factorization Machine,是比较早期的特征交叉方法,那时候用的还是线性回归,它希望对所有特征两两进行交叉进行二次项的建模:
\[y = w_0+\sum_{i=1}^n w_ix_i + \sum_{i=1}^n\sum_{j=i+1}^n \textcolor{blue}{w_{ij}}x_ix_j\]但是交叉特征的系数是对称矩阵,矩阵很大,参数 $\textcolor{blue}{w_{ij}}$ 数量很多,而且很稀疏,FM使用低秩近似来减小模型参数量:
\[y = w_0+\sum_{i=1}^n w_ix_i + \sum_{i=1}^n\sum_{j=i+1}^n \textcolor{blue}{<v_i, v_j>}x_ix_j\]这里 $v_i$ 和 $v_j$ 是第 $i$ 和第 $j$ 个特征的embedding。FM给每个特征分别学习一个embedding,两个特征的embedding的内积作为二次项系数,而不是直接把二次项系数 $\textcolor{blue}{w_{ij}}$ 作为参数。在深度学习的场景下,由于 $x_i$ 和 $x_j$本身也是embedding,二者都是可学习参数,完全可以把 $x_i$ 和 $v_i$ 合并,这样所谓的FM交叉就只是把 embedding 求内积得到的新的特征。
FM实现起来也很简单,给每一个特征对应一个 $d$ 维的embedding,假设一共有 $n$ 个特征,不用低秩分解的话,有 $n^2$ 个参数;如果用低秩分解的话,则只有 $nd$ 个参数,通常 $d$ 远远小于 $n$。直观理解,这个embedding学到的是特征之间的关联性,越相关的特征会越相似,内积越大。
FM也有一定的缺陷,例如难以刻画更复杂一些的特征,比如日期,于是有了FFM的改进。FFM也很简单,FM是每个特征学一个embedding,而FFM是学多个embedding,每个embedding称为一个特征域。每个特征还会赋予一个域的id,第$i$个特征的域ID记为$f_i$。在计算交叉系数时,会根据对方的域取出embedding求内积$v_{i,f_j}^Tv_{j,f_i}$。引入域的概念后,可以更精细的进行建模。
如何确定交叉哪些特征?
如果可以的话,应该直接对所有特征进行交叉。但是特征数量太多的情况下这是不可行的,此时需要挑选一些特征进行交叉。挑选时可以根据对特征的理解去交叉。更自动化的方法是根据特征的重要性,选择最重要的特征进行两两交叉。除此之外,可以使用self-gated的方法,筛选出交叉之后重要的特征,把不重要的去掉。
Neural Interaction
All Interaction,输入是(B, N, D)的张量,把N个特征用linear层压缩成16个特征得到(B, 16, D),然后N个特征和这16个特征两两交叉得到(B, N, 16),最后reshape成(B, D * 16)。
Neural Interaction是把(B, N, D)里面的N个特征两两求hardmard积得到(B, N * N, D),这得到的是对称矩阵,所以可以去掉一半,得到(B, N * (N+1) / 2, D)的特征,用MLP把特征数量压缩得到(B, 16, D),最后reshape成(B, D * 16)。
两者的区别是特征数量压缩的位置不一样,前者在交叉之前就压缩了,后者在交叉之后才压缩,理论上后者更好,因为先进行了完整的压缩。如果再引入一些门控机制效果应该挺好的。
排序模型
前面介绍了推荐系统中常见的特征,这些特征会被转化为向量输入到模型中,下面介绍经典的推荐系统模型。
线性回归
线性回归实现上通常直接对embedding求和,经过sigmod函数预测点击率等指标。以前还会用GBDT+LR(2014年Facebook提出来的),用GBDT实现自动化特征工程,用LR进行预测。这里GBDT的特征工程指的是根据特征是否落在某个叶子上决定是1还是0,于是得到一个很长的0和1组成的向量送入LR。不过在深度学习时代,这种已经几乎完全被embedding的思想取代了。如果以embedding都视角来看,GBDT+LR实质上也是在学embedding,因为一个特征会被多颗树使用,于是一次预测中,一个特征会对应多个叶子节点中的1,这些1被LR加权,这些权重可以被理解成是这个特征的embedding。
Wide & Deep

如上图所示,Wide&Deep把线性回归和MLP进行了结合,来预测CTR:
\[p_{ctr} = \sigma({\rm Linear}(x_1) + {\rm MLP}(x_2))\]这里 $x_1$ 和 $x_2$ 分别是一堆特征组成的向量,$\sigma$ 是sigmoid激活函数。wide部分用线性回归,主要负责记忆一些明确的规则,比如(uid, brand)这个交叉特征,如果是1表示用户买过这个牌子,0表示没买过。如果uid喜欢这个牌子,那么这个牌子的商品点击率应该很高,把它直接加到最后的输出上影响更直接。Deep部分用MLP,提供非线性的建模,负责学习更复杂的规则以及泛化。通常MLP会被替换成一些更复杂的模型。
尽管 Wide&Deep 是一个2016年的模型,比较老了,但是至今依旧被广泛使用。Wide的部分以深度学习的视角来看可能有些奇怪,但是搭配上能够使参数稀疏的FTRL算法后,可以认为至少不会带来负向的结果。后续的很多模型上的变体都是对MLP的修改,包括各种交叉网络、注意力网络等等。
用户行为建模
推荐系统是为了给用户推荐感兴趣的内容,而用户的绝大部分兴趣都是通过他的行为体现出来的,因此,用户行为特征是最重要的一类特征,因而用户行为建模也至关重要。
Match特征
用户行为建模的一种方式是构建 match 特征。Match 特征用于刻画用户历史行为与 item 属性等交互数量。比如用户之前交互了100个商品,这100个商品有10个都是电子产品,那么 match 特征就是整数10。这个例子的 match 是电子产品这个类目的 match 数量,也可以是别的 match,比如 item id的 match,即用户之前就交互过这个商品,而且反复的看。
match 特征不为0,说明用户已经和它交互过了,这还要继续推荐吗?答:1. match特征有不同的粒度,有一些粒度是可以泛化的,比如和某个类目的交互次数;2. 对于广告推荐,广告是跨平台的,可能会在不同平台重复看到一个广告,据说反复的推同一个广告是有效的。
行为序列建模
Match特征只是比较粗糙的对用户行为的刻画,更精细的做法毫无疑问是直接把用户交互过的 item 全部作为模型的输入,用户交互过的 item 是一个序列,这种序列特征完全表示了用户过去的行为,用户交互过的各种 item 体现了用户的多样的兴趣,并且序列还能展现用户的兴趣变化,是非常重要的特征。
行为序列可以根据交互行为的不同得到不同的序列,有点击的序列、点赞的序列、评论的序列等等。除此之外,还可以根据用户交互过的 item 的属性列表得到不同的序列,比如交互过的商品ID序列、商品类目序列、品牌序列等。
行为还可以划分浅层行为和深层行为。对于内容推荐而言,点击是比较浅层的行为,点赞收藏是更深层的行为,深层行为占比更少但是更能体现用户兴趣;对于电商而言,点击→加入购物车→购买 是逐渐深层的行为。
youTubeDNN(2016)首次引入了序列特征,对序列特征求sum pooling得到固定长度的MLP输入。在召回阶段,在 user 侧对用户交互过的 item 特征做poolling毫无疑问可以让得到的embedding与需要检索的 item 的embdding更相似;在排序阶段,这种序列特征告诉了模型用户对于候选的 item 是否有明确的喜好。
DIN(2017) 把需要排序的物品,和序列特征求注意力并加权求和得到特征,以此代替简单的取平均。DIN的注意力通常是拼接之后经过MLP降到一维,而不是 transformer 那种内积,并且也不经过 softmax。通常考虑到计算量的问题,DIN使用的序列长度只有几十,不会太大。通常每个 item 都有很多特征,比如id特征,也比如 item 所属的类目特征、语义特征等等,一般的处理方式是把这些特征 sum pooling 变成这个 item 的一个特征,在经过注意力处理得到固定维度的序列特征。DIN 的query特征选择比较有讲究。如果是信息流场景,用户没有明确的浏览意图,可以使用候选 item 的泛化特征进行sum pooling,这样可以检索到更泛化的 item 。如果是搜索场景,用户意图明确,可以使用搜索用的文本信息。
在 DIN 之后,对序列建模也有很多方法,不过用得没有 DIN 广泛。DIEN(2018)序列的时间信息,引入 GRU+Attention 的建模;DSIN(2019)在序列建模中引入了session的概念,表示用户短期集中的行为。例如新出了一个游戏,用户可能会集中刷很多相关的视频,用户看了个番剧,也会集中刷一些相关的视频,session内的用户行为是高度同构的。DSIN按30min的时间间隔去划分session,session内的行为用Transformer编码并average pooling为一个token,之后用双向LSTM编码session级别的token去建模session级别的兴趣变化;MIMN(2019)希望建模长序列,因为这篇论文发现序列越长,模型预测越准;SIM(2020) 提出了一个非常有效的解决长序列的方法,把序列长度增大到了几千。思路也很简单,从长序列中选 topK 来得到短序列,再使用 DIN。topK 可以根据物品类目直接用规则筛选(hard搜索),也可以用近似K近邻(soft搜索,效果好,但计算量大且需要额外训练得到embedding);ETA(2021),认为SIM的一阶段hard搜索是离线的,不够好,为此基于二阶段的embedding用SimHash去进行一阶段的快速检索,效果比SIM的hard搜索好但是比Soft搜索差。TWIN(2023)也是SIM模型的改进,在两个阶段共用参数和搜索策略提高一致性,两个阶段都用Attention,效果比SIM好不少。但是都用Attention计算量大,所以核心就是怎么加速一阶段。TWIN的思路是一阶段搜索只使用ID、类目等可以离线计算的item固有特征,并且交叉特征只作为attention bias而不需要算attention,搜索时只需要look up再计算单Head的attention即可,二阶段可以使用更多特征以及Multi-head。
MLP的替代模型
Deep Cross Network系列
MLP 不善于学习二次或更高次的函数,FM 在输入 MLP 之前做交叉,多少有些不优雅,而 DCN 希望通过设计神经网络模型让模型更善于交叉,能达到比 MLP 更好的效果,召回和排序都能用。
DCN(2017)。对于 DCN 的输入$x_0$,第$l$层输入为$x_l$,DCN 的计算公式是: \(x_{l+1}=x_l+x_0x_l^Tw_l+b\) 其中$w_l$和$b$是模型参数。可以看出来,和 MLP 不同的是 MLP 是参数矩阵对输入进行映射,而 DCN 是和输入求外积进行交叉,得到矩阵再对模型参数进行映射。这么做其实就是得到了和输入的二次项:
\[\boldsymbol{x}_1 = \boldsymbol{x}_0 \boldsymbol{x}_0^T \boldsymbol{w}_0 + \boldsymbol{x}_0 = \begin{bmatrix} x_{0,1} \\ x_{0,2} \end{bmatrix} [x_{0,1}, x_{0,2}] \begin{bmatrix} w_{0,1} \\ w_{0,2} \end{bmatrix} + \begin{bmatrix} x_{0,1} \\ x_{0,2} \end{bmatrix} = \begin{bmatrix} w_{0,1}x_{0,1}^2 + w_{0,2}x_{0,1}x_{0,2} + x_{0,1} \\ w_{0,1}x_{0,2}x_{0,1} + w_{0,2}x_{0,2}^2 + x_{0,2} \end{bmatrix}\]如果把公式改成
x = x + ((x_0 @ x^T) * W_l).sum(dim=1) + b
可能效果还好点,不需要共享参数。
DCNv2(2020)也考虑到了这个缺陷,于是把公式改成了:
UV是低秩矩阵。这个可以理解为把ResNet的加法改成了乘法,并且相加的都是$x_0$。除此之外,DCNv2还有一个创新点是引入了moe,不过这个和DCN的核心思路特征交叉没啥关系,这里就忽略掉了。Gated GCN(2023)在DCNv2的基础上加了一个gate操作:
\[x_{l+1} =x_l+x_0 \odot (Wx_l+b)\odot \sigma(Vx_l+c) =x_l+x_0 \odot \text{GLU}(x_l)\]后半部分其实就是GLU啊,相当于把DCN里面常规的MLP换成了GLU。
DCN系列还有一些其它的改进,例如xDeepFM(2018)。DCN是多个特征融合后的向量和输入做交叉,而xDeepFM是多个特征组成的矩阵和输入做交叉,二者都通过Hadamard积做交叉。假设输入 $m$ 个特征,每个维度是 $D$ 维,输入就是一个矩阵 $X_0 \in \mathbb R^{m\times D}$。网络的第 $k$ 层也是一个矩阵,只是特征数量发生了变化,记为 $X_k\in\mathbb R^{h_k\times D}$。xDeepFM让第 $k$ 层的 $h_k$ 个特征和 $X_0$ 两两求Hadamard积得到 $h_k\times m\times D$ 维的张量,并且用参数 $W_{h}\in R^{h_k\times m}$ 对这 $h_k\times m$ 个向量进行加权求和,$h_{k+1}$ 个这样的参数就得到了下一层的 $h_{k+1}$ 个向量。把这样的结构堆几层得到的网络叫Compressed Interaction Network(CIN)。CIN比较创新的地方是把MLP的向量形式的特征扩展到的矩阵形式,对标量的加权求和扩展到了对向量的加权求和,每一层的超参数也从MLP的隐藏层维度变成的向量个数 $h_k$。xDeepFM模型则是把CIN作为一个额外的塔加在Wide&Deep上。
MMCN是字节提出来的一个模型,缝合了多种交叉方式,把MLP每层的向量分成多段,每段称为一个head,head之间用不同的交叉方式,同时结合了交叉结果的sum pooling。
注意力模型
LHUC 给激活值学一个scale,取值范围是$[0, 2]$,实现方法是把一些合适特征作为门控输入,过sigmoid激活函数再乘以2得到scale,把这个scale乘到MLP到激活值上。这里哪些特征适合作为门控控制其它特征需要根据业务人为设计。
\[f_{recycle}(x) = {\rm Relu}(\textcolor{red}{w_{1}} \cdot (\textcolor{blue}{x \odot 2\sigma(w_{2} \cdot {\rm Relu}(w_{1} \cdot x + b_{1}) + b_{2})}) + \textcolor{red}{b_{1}})\]上面公式中的RecycleNet算是LHUC的改进版本,用在降维的地方,属于模型的魔改,不好说为什么有效。公式中蓝色的部分是$x$对自己的门控,而外层复用了参数$w_1$和$b_1$,相当于先对自身rescale一遍,再降维,可能的好处是在降维前对特征重新筛选了一遍,通过门控机制选择了适合降维的特征。
SENet原本是计算机视觉领域的经典模型,设计了一个通道注意力机制,是一个稳定涨点的模块。在推荐系统中可以用来对多个特征进行注意力,也是为一种特征之间的交互方式。
多任务学习
在推荐的场景下,多任务学习指的是模型会预测多个指标,例如点击率、点赞率、收藏率等等。预测多个指标的原因在于,单独预测预测一个指标并不可靠,不能完全体现用户的兴趣。例如,如果让模型只预测CTR,模型会喜欢推荐标题党的内容,这种内容用户可能会点击,但大概率不感兴趣,多任务学习通过预测多个指标从多个维度建模用户兴趣(interest)和参与度(engagement)。
多个目标最后还是要融合成一个分数进行排序,最简单、最常见的方法是加权求和,这里的权重需要用ab测试调。
指标预测
常见的指标例如点击率、点赞率用交叉熵损失训练即可,但是也有一些指标并不太容易直接用分类或回归来预测,例如视频观看时长。
采样纠偏
由于推荐系统中负样本太多,通常会对负样本进行下采样,这样能让正负样本更均衡一点,同时也减少训练成本。但下采样会导致训练得到的模型预测的点击率等指标相较于实际点击率偏高。虽然对于排序来说只需要相对值,大家都偏高等于没有偏高,不处理也没有影响。但是对于广告推荐而言,这些指标会参与对广告竞价的计算,需要准确的值,为此需要纠偏。下面进行推导如何进行纠偏。首先推导对数几率:
\[\begin{aligned} p(1|x) &=\sigma(x) =\frac{1}{1+e^{-z}}\\ z &=\text{MLP}(x) \end{aligned}\]这里的 $z$ 一般叫logit,从sigmoid函数可以推出它等于正负样本概率的对数:
\[z = \ln\frac{p(1|x)}{p(0|x)}\]也就是所谓的对数几率,在使用二元交叉熵进行分类的情况下,模型实质上在回归预测对数几率。接下来使用贝叶斯公式,看看对数几率和正负样本比例有什么关系:
\[\begin{aligned} z &= \ln\frac{p(1|x)}{p(0|x)} = \ln\frac{\frac{p(x|1)p(1)}{p(x)}}{\frac{p(x|0)p(0)}{p(x)}} = \ln\frac{p(x|1)p(1)}{p(x|0)p(0)} = \color{red}\ln\frac{p(x|1)}{p(x|0)} + \ln\frac{p(1)}{p(0)} \end{aligned}\]$\frac{p(1)}{p(0)}$ 就是正负样本比例,假设负样本采样比例是 $r<1$,那么正负样本比例就变为 $\frac{p’(1)}{p’(0)}=\frac{p(1)}{rp(0)}$。使用下采样后的训练集进行训练对数几率 $z’$ 为:
\[\begin{aligned} z' = \ln\frac{p'(x|1)}{p'(x|0)} + \ln\frac{p'(1)}{p'(0)} = \ln\frac{p(x|1)}{p(x|0)} + \ln\frac{p(1)}{p(0)} - \ln r = \color{red}z - \ln r \end{aligned}\]由于正负样本比例不影响 $p(x|y)$,所以 $\frac{p’(x|1)}{p’(x|0)}=\frac{p(x|1)}{p(x|0)}$,再把式子第二项替换掉就得到了下采样前后的logit之间的关系。这个式子表明,只要在训练的时候给logit加上一个 $-\ln r$,测试的时候再去掉,就能得到实际预测的点击率。直观来说,$-\ln r > 0$,相当于通过人为增大预测的概率来抵消掉负样本下采样带来的点击率偏高,之后再去掉就能恢复真实的点击率。
视频观看时长预测
视频没有点击率这样的指标,一般会预测视频的“平均观看时长”。这个指标看起来不是很好预测,但实际上很简单——训练的时候使用观看时长加权的交叉墒,serving的时候对logit取指数就是平均观看时长。考虑一共发送了 $N$ 个视频,其中正样本有 $k$ 个,分别观看了 \(\{T_i\}_{i=1}^k\) 的时长,负样本则没有点击。使用如下的loss进行训练:
\[\mathcal L = - T_iy_i\ln(1-p) - (1-y_i)\ln p\]就是给正样本加了个权,相当于有 $\sum_i T_i$ 个正样本,$N-k$ 个负样本。考虑到logit的指数是正负样本比例:
\[e^{f(x)}=\frac{p}{1-p}=\frac{\sum_i T_i}{N-k}=E[T]\frac1{1-\frac{k}{N}}\approx E[T]\]因此$e^{f(x)}$ 近似等驾驭预测这个视频的平均预测时长,实际上会略微偏高一点点(因为正样本比例很小)。
经典模型
多任务学习的难点是不同任务之间相关性(correlation)不同,有些任务的correlation比较低,有的则比较高,有的甚至存在冲突。例如标题党视频的点击率可能高但是完播率低,又比如争议性话题的用户参与度(engagement,比如评论)可能高但是点赞率低。由于不同任务的correlation不同,使用一个公共的网络接上不同的head预测不同目标的效果是不够好的,让不太相关的任务共享表征会导致两个任务的performance都下降(负迁移现象)。为此,有一些专门针对多任务的模型被提出,其中最具代表性的是MMoE,即Multi-gate MOE。

MMOE在MOE的基础上给不同任务引入不同的门控来实现多指标预测,每个目标在不同专家的侧重点不同,能够较好的建模差异大的目标。MMOE提取的表征后面接不同的head来预测不同的目标。通常expert数量设成两三个即可,如果expert比较小,可以设多一些。为了避免极化,也就是某个专家始终不被使用,会对softmax进行dropout,在训练时随机drop一些专家。
MMOE的缺陷是所有任务共享一些专家,只是每个专家分配到的权重不同,因此还是存在一定的跷跷板效应,即一个任务效果变好,其它的就会变差。关于这个现象的一个例子是视频播放的VCR和VTR预测,VCR(View Completion Rate)指视频观看比例,通过回归预测;VTR(View Throught Rate)是指视频是否有效播放,当视频播放时长大于设定的阈值时视为有效播放,通过二分类预测。VCR和VTR是相关但又不完全相关的关系,首先他们肯定是相关的,不想关则的例子是对于长视频完播率肯定比较低,但是VTR可以很高,例如只要播放5s就算有效观看。并且,VCR和VTR还和样本有关,在WIFI自动播放的场景下VTR会偏高,但是VCR低。当使用不同的多任务模型进行VCR和VTR目标的预测时,二者总是很难同时提高。MMOE在其中算好的,不够MMOE虽然能建模差异,但是还是更倾向于学习公共的pattern。
为了解决上述跷跷板效应,腾讯提出了PLE,拿了RecSys 2020的best paper。其思想是给每个任务增加自己独有的一些专家(一般就一个),避免不同任务之间冲突,并保留每个任务共享的专家学习(两三个)共享的表征:
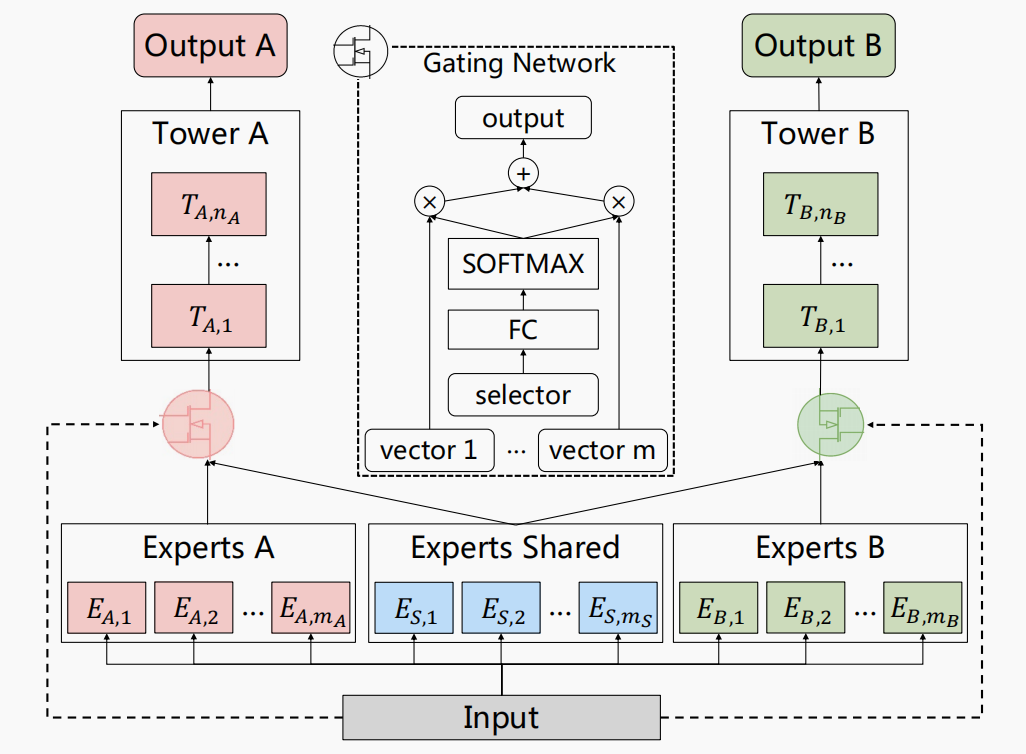
共享专家在gating的时候可以从所有expert加权表征,而独有专家只能从自己和共享专家加权表征。这样的模型称为Customized Gate Control(CGC),多层的CGC就是PLE。一般CGC会稳定的比MMOE更好,而PLE是否比CGC更好要看情况,比如数据量,需要多试试。小红书的某业务使用了两层的PLE,网上也有人说他们的业务CGC更好。
多场景建模
前面介绍的MMOE和PLE模型都进行的是多任务建模,是一个模型预测多个目标,是多种输出。而多场景则是多种输入,用一个模型处理不同场景的业务,减少模型维护成本。当然实际上MMOE、PLE也能用于多场景建模。
STAR(2021)模型是快手提出的多场景建模方法。创新点有3个:其一是星形拓扑网络,其二是Partition Normalization(PN),其三是辅助网络。星形拓扑网络针对N个场景训练N+1个结构完全相同的模型,其中每个domain分配一个模型专门学习这个domain的预测,而多出来一个模型用来学习每个domain共有的东西。在预测的时候,domain模型和公共模型的权重会element-wise相乘得到一个新的模型来预测,bias则是相加。为什么这里权重不用相加呢?因为$(W_1+W_2)x=W_1x+W_2x$,这样不如$(W_1\odot W_2)x$把两个模型耦合得更深。
PN是Batch Normalization(BN)在多场景下的改进,因为BN要求样本独立同分布,但是多场景建模的情况下不同场景肯定分布不同,因此Partition Normalization会在BN的基础上给每个domain使用专有的均值$\textcolor{red}{E_p}$和方差$\textcolor{red}{Var_p}$,同时学习专有的$\textcolor{red}{\gamma_p}$和$\textcolor{red}{\beta_p}$:
\[x' = (\gamma \odot \textcolor{red}{\gamma_p}) \frac{x-\textcolor{red}{E_p}}{\sqrt{\textcolor{red}{Var_p}+\epsilon}} + (\beta+\textcolor{red}{\beta_p})\]辅助网络比较简单,就是把domain特征的特征输入一个比较小的网络作为辅助网络,预测logit和星形拓扑网络的输出相加再过sigmoid得到输出。
PEPNet(2023)也是快手提出的多场景建模模型,其实就是LHUC+MOE:每个指标用一个expert预测,不同的场景则把场景特征作为LHUC的门控输入,对每个特征进行scale。除此之外,也会用uid、item id等特征作为另一个LHUC的门控,对每个expert的神经元进行scale。在推荐中,LHUC是一个非常重要且常见的结构,在PEPNet这里也得到了体现。
评估指标
排序模型基本都是进行二分类的预测,但进行二分类的目的不是为分类,而是进行排序,因此分类准确率是没有意义的,预测概率的相对大小才是核心,故而大多使用AUC。AUC全称是Area Under Curve,定义为ROC曲线下方的面积,或者说0到1之间的积分值,含义是任取一个正样本和负样本,模型预测的正样本得分大于负样本得分的概率,AUC衡量了模型对正负样本的区分能力,下面先说明PR曲线和ROC曲线是什么,再介绍AUC。
-
PR曲线:Precision-Recall曲线,设置不同的分类阈值,$(R,P)$形成的曲线。
-
ROC曲线:Receiver Operating Characteristic 曲线,设置不同的分类阈值,$(FPR, TPR)$形成的曲线。
- FPR:False Positive Rate,负样本中预测为正的比例,表示虚报(正类)的比例,越低越好。
- TPR:True Positive Rate,就是召回率。
和P,R是一对矛盾的指标不同,FPR和TPR都随阈值递增,如果阈值越高,召回率就越低,虚报比例也越低。如果把模型对所有样本的打分进行排序,在阈值上方的是FP和TP,阈值越高,FP和TP都越低,而总的正样本数量和负样本数量一定,所以两个指标都变低。
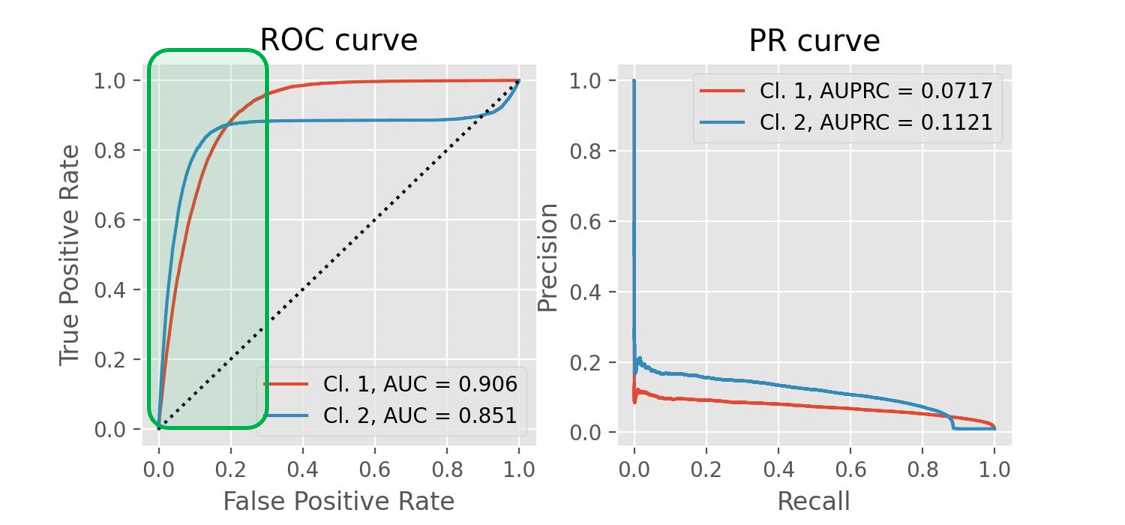
从左往右阈值降低
ROC曲线中,我们关注曲线是否陡峭(越陡越好,图中绿色的区域),即虚报不多的时候,召回率就能达到较高的值,同时这样模型对于阈值也比较鲁棒。
TPR和FPR各自关注正类和负类内部的准确率,因此ROC曲线无视类别是否平衡,适合类别不均衡情况下的分析。
AUC
Area Under Curve,ROC曲线下方的面积,或者说0到1之间的积分值,含义是任取一个正样本和负样本,正样本得分大于负样本得分的概率。
PR曲线和ROC曲线的性质是如果 $A$ 包裹 $B$ 的话,说明 $A$ 全面优于 $B$,但通常不是完全包裹,而是有交叉的,此时可以用AUC评估。如果AUC高,说明曲线接近右上角,意味着在给定阈值下,阈值上方的大多数都是TP,也就是模型能对正负样本的区分能力强,或者说排序能力强。

证明参考上图,对于离散的ROC曲线,从高到低遍历模型预测的概率集合,以这个概率对阈值。如果等于阈值的只有一个正样本,则上升一格;只有一个负样本,则往右一格;有p个正样本和n个负样本,斜向上走(n, p)。代码实现AUC计算的思路是统计每个阈值的正负样本数量,然后遍历阈值去计算相邻点之间的梯形距离。下面也给出公式证明:
\[\begin{aligned} AUC &= \frac1{m_+}\sum_{x_+} (\frac1{m_-}\sum_{x_-}\mathbb I[f(x_+) > f(x_-)]) \\ &= \frac1{m_+m_-}\sum_{x_+}\sum_{x_-}\mathbb I[f(x_+) > f(x_-)] \end{aligned}\]$\frac1{m_-}\sum_{x_-}\mathbb I[f(x_+) > f(x_-)]$表示比 $f(x_+)$ 分数低的负样本的比例,或者说负样本得分比这个正样本得分低的概率,对应上图中一行的面积(蓝色区域)。把所有行累加,就得到了AUC,也反映了任取一个 $x_+$ 和 $x_-$,$f(x_+)>f(x_-)$ 的概率。
GAUC
Group AUC,就是按一定规则把样本划分为一定的group,在group内计算auc,之后把每个group的auc按group大小加权求和。它的一个特例是UAUC(User AUC),也就是看每个用户产生的样本的AUC,能更好地反映模型的好坏,但是由于每个用户的样本一般都不多,所以很多时候也不是一个好的指标。
总结
推荐系统中深度学习模型和CV、NLP相比相对简单,模型需要学到的是一些相对浅层的规律,大致是在学习给用户推荐用户看过的相似的物品,这和CV、NLP需要让模型学到深层的pattern有很大差异。
精排模型的设计,一个趋势是让一个模型做更多的事情,减少模型的维护成本。推荐系统由于用户和内容的多样性,不得不引入多场景的建模,PEPNet就是一个直观合理的方案,把场景特征作为特殊的输入控制模型的其它部分。STAR模型PN肯定是合理的,但是权重相乘的操作看起来没有足够的道理,目前还不太能get到。STAR模型引入额外的塔,最后在logit做简单的加法来融合的思想在推荐里面很常见,Wide&Deep也可以理解为是这种思想,即把特征加更靠近输出的部分。